Gson使用方法:
Gson.fromJson(String json, Class clazz)
所以从 fromJson 开始解析
Gson.java
fromJson() 有多个重载函数,最终都会调用下面这个
|
|
|
|
上面 getAdapter 代码中会遍历存储 TypeAdapterFactory 的 factories 来找匹配的 TypeAdapter
那 factories 是什么时候添加的?
|
|
我们再回到 fromJson() 中,刚才分析到了 getAdapter()
接下来继续
|
|
找到匹配的 typeAdapter 就会调用其 read() 函数进行解析,此处我们着重分析 Gson 的反射实现原理,所以此处查看 ReflectiveTypeAdapterFactory 中 adapter 的 read() 实现
ReflectiveTypeAdapterFactory.java
在 ReflectiveTypeAdapterFactory 中有内部类 Adapter 如下,真正调用的是其 read() 函数
|
|
至此整体大概的解析完成,总结一下整体流程,附上流程图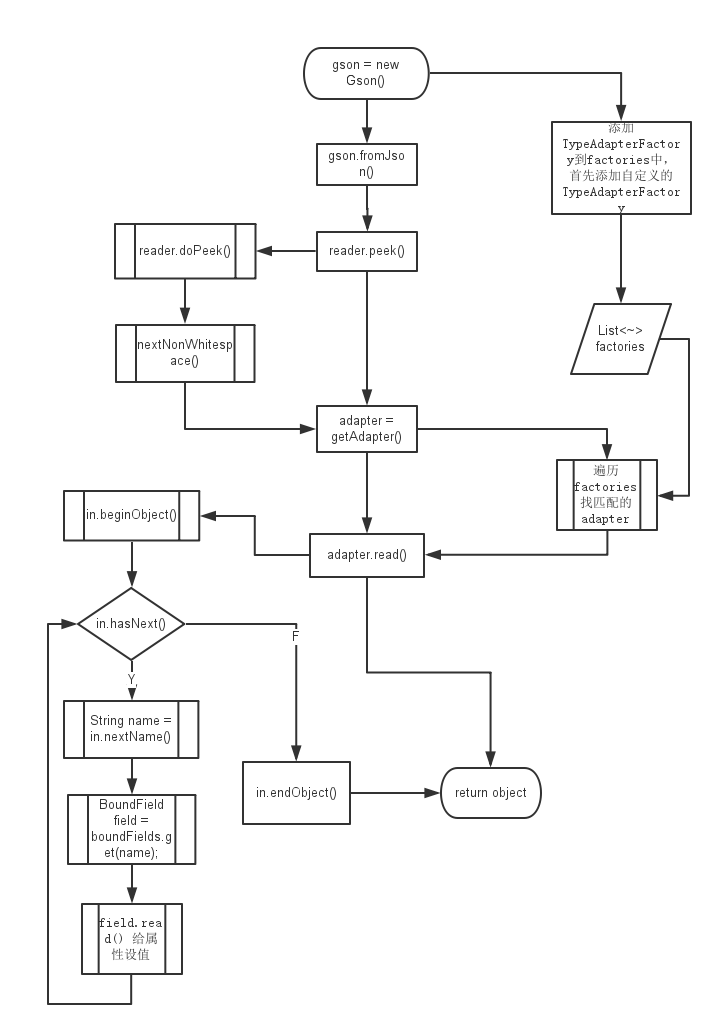
最后介绍一些比较重要的函数
上述代码中的 in.beginObject() in.hasNext() in.nextName() in.skipValue() 都会调用 Reader 中的 doPeek(),其他的代码也会调用 doPeek() 所以这个函数非常重要,接下来解析此函数
JsonReader.java
- doPeek()1234567891011121314151617181920212223242526272829303132333435363738int doPeek() throws IOException {// 每次调用 beginXXX 的时候都会调用 stack[stackSize ++] = JsonScope.XXXint peekStack = stack[stackSize - 1]; // 获取 stack 顶部标志if (peekStack == JsonScope.EMPTY_ARRAY) {stack[stackSize - 1] = JsonScope.NONEMPTY_ARRAY;} else if (peekStack == JsonScope.NONEMPTY_ARRAY) {int c = nextNonWhitespace(true); // 获取下一个非空字符switch (c) { // 解析字符,下面的代码和这个类似,就省略了case ']':return peeked = PEEKED_END_ARRAY;case ';':checkLenient(); // fall-throughcase ',':break;default:throw syntaxError("Unterminated array");}} else if ( ... ) {// ...}int c = nextNonWhitespace(true);switch (c) {// ...}int result = peekKeyword();if (result != PEEKED_NONE) {return result;}result = peekNumber();if (result != PEEKED_NONE) {return result;}return peeked = PEEKED_UNQUOTED;}
peek() 函数内部基本上是对 doPeek() 的调用
JsonReader.java
- nextNonWhitespace()12345678910111213141516171819202122232425262728293031323334353637383940414243444546474849505152535455565758596061626364656667686970717273747576private int nextNonWhitespace(boolean throwOnEof) throws IOException {char[] buffer = this.buffer;int p = pos; // pos 表示当前解析的位置int l = limit; // limit 表示最后位置while (true) {if (p == l) { // 说明 buffer 已经读完了pos = p;if (!fillBuffer(1)) { // 从 instream 中填充 buffer, 参数表示最少需要填充多少, 返回表示是否能满足最少需要的break;}p = pos; // 更新数据l = limit;}int c = buffer[p++]; // 获取当前字符if (c == '\n') {lineNumber++;lineStart = p; // 当前行从哪个位置开始continue;} else if (c == ' ' || c == '\r' || c == '\t') { // 过滤空格等字符continue;}if (c == '/') { // 读取 /**/ 和 // 的注释pos = p;if (p == l) {pos--; // push back '/' so it's still in the buffer when this method returnsboolean charsLoaded = fillBuffer(2);pos++; // consume the '/' againif (!charsLoaded) {return c;}}checkLenient(); // 检测兼容性,先忽略char peek = buffer[pos];switch (peek) {case '*': // 读取 "/**/" 注释pos++;if (!skipTo("*/")) {throw syntaxError("Unterminated comment");}p = pos + 2;l = limit;continue;case '/': // 读取 "//" 注释// skip a // end-of-line commentpos++;skipToEndOfLine();p = pos;l = limit;continue;default:return c;}} else if (c == '#') { // 读取 '#' 的注释, 直接跳到下一行pos = p;checkLenient();skipToEndOfLine();p = pos;l = limit;} else { // 返回解析到的字符,并重置pospos = p;return c;}}if (throwOnEof) {throw new EOFException("End of input"+ " at line " + getLineNumber() + " column " + getColumnNumber());} else {return -1;}}
在 nextNonWhitespace 中会调用到 fillBuffer() 来填充,接下来看一下 fillBuffer() 的实现
这样 Gson 使用反射来解析 json 大体上解析完了,接下来自己实现了一个简单的Json解析器,地址如下:Json解析器